
Murat successfully defended this work on July 14, 2006, before his committee:






Dr. Ehat Ercanli-Dr. Can Isik-Dr. Marek Podgorny-Dr.
Daniel J. Pease-Dr. James W. Fawcett (Advisor)
Electrical Engineering and Computer Science
Dr. Yildiray Yildirim (Chair) -
School of Management
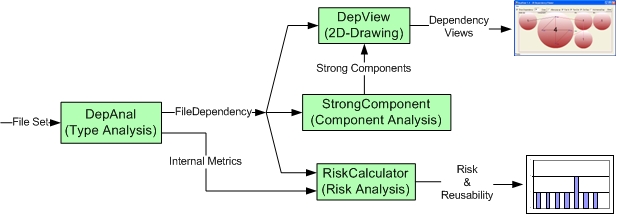
Data Flow During analysis and visualization of software system’s quality
Today, software is found in almost all systems, vehicles,
communication devices, medical equipments, and entertainment, for example. The
size and complexity of these systems has grown continuously over the last forty
years – the time span for modern computing. The latest release of the Windows
operating system, called Vista, is expected to be more than fifty million lines
of code, about 40% bigger than the previous version.
Some of the reasons for this are numerous feature demands and the need to
support multiple platforms, and need for compatibility with legacy software and
hardware. Each line of code, in these large systems, requires perhaps several
technical decisions, often, but not always simple. The sheer volume of this
decision making process is daunting. No single human can fully understand a
system of high complexity. To help ameliorate this problem, systems are
decomposed into subsystems, libraries, modules, and classes. Most of these
components have interdependencies, in order to provide services, one to another.
However, in systems of great size, the dependencies often become a dense web of
relationships. It is exactly this problem on which we focus in this research.
We propose that static dependency structure is an important element to
understand the state of large software system. We conduct various analyses using
well-known existing open-source, commercial and expert developed projects,
including our own projects to evaluate the overall effectiveness of our
approaches. We detect structural problems in large software development
projects, and present a structure metric to rank software files according to
their risk contribution to the software system. Additionally, we present a model
that indexes software components according to their potential for reuse. We
design and conduct experiment to investigate the impact of change in one file on
other files. Furthermore, we provide tools needed to support analysis, project
visualization and monitoring. Finally, we investigate corrective procedures and
simulate their application, monitoring improvements in observed defects.
