Initial Thoughts:
There is currently a lot of technical interest in "Big Data". Extreme examples are: data collection and analyses from the Large Hadron Collider, the Sloan Sky Survey, analyses of Biological Genomes, collecting data for global climate models, and analyzing client interactions in social networks.
Conventional SQL databases may not be well suited for these kinds of applications. While they have worked very well for many business applications and record keeping, they get overwhelmed by massive streams of data. Developers are turning to "noSQL" databases like MongoDB, CouchDB, and Redis to handle massive data collection and analyses.
SQL Data Model:
Traditional SQL databases provide a very well understood data management model that supports the ACID properties, e.g., each transaction is Atomic, leaves managed data in a Consistent state, appears to operate in Isolation from other transactions that may operate concurrently, and at the end of the transaction the database state is Durable, e.g, is persisted to a permanent store.
SQL data is normalized into tables with relationships. This matches very well with data models where many records may be associated with the same data. If we build a books database, for example, many books may be associated with the same publisher information. We link the book information with a foreign key relationship to publisher information in another table to avoid duplicating the same publisher data in every book record. Many to many relationships are modeled by linking tables often containing two foreign keys. For the books database a book may have several authors and an author may have published more than one book. So the link table holds records each of which capture the association of a book with an author. If a book has two authors there are two records with that book key, one for each author.
Each SQL Table has a fixed schema that captures the type of the records in the table. A record in the books table might contain the book's name and date of publication. SQL database designs emphasize data integrity and structuring models in a fixed normalized tabular form. Queries into the database usually join data from several tables to build a complete description of the results to be returned.
noSQL Data Models:
The data models used by noSQL databases are usually based on key/value pairs, document stores, or networks. noSQL processing favors modeling flexibility, the ability to easily scale out across multiple machines, and performance with very large datasets. For that flexibility they give up real-time data consistency, accepting application enforced eventual consistency. They give up a formal query mechanism (hence the name). And, they may give up Durability guarantees by only occasionally writing to persistant storage in order to provide high throughput with large volumes of data.
The choice to use SQL or noSQL data management is driven by the nature of its uses. Below we discuss Project #5, an application that builds a data management service for a large collaboration system composed of federated servers. That seems ideally suited for noSQL data managment.
Goals of a noSQL Implementation:
The noSQL model has goals that often prove to be difficult to implement with SQL databases. A noSQL database is designed to support one or more of the following:
- Very large collections of data
- High throughput with data from streams
- support tree or graph models for its data
- support heterogenious collections of data
A noSQL model may use a hashtable to store key/value pairs incurring essentially constant time lookup and retrieval of its data, e.g., time independent of the size of the data. However, when the size of the managed data requires sharding, the constant time lookup and retrievel may be compromised by processing necessary to locate shards that contain the data we need to retrieve. We need to think about things like managing multiple shards in memory using a Least Recently Used mapping strategy, much like a virtual memory system. We will likely think about using in-memory indexes to keep track of which shards hold specific data items or categories of items. For some applications it may be appropriate to shard data into time-related batches, e.g., data collected in a day or a week.
With SQL data management all data is managed the same way. The only flexibility is how we partition the data into tables and possibly shard data across multiple machines. Changing the schemas and sharding strategy can be quite difficult to implement. Using noSQL databases we have a lot more flexibility in configuring data and it is easier to change schemas.
The good news is that configuring data, managing schemas, determining when and how to persist to durable storage, and maintaining consistancy is, with noSQL, up to the application. The bad news is that it is up to the application.
Implementing a noSQL Database:
In CSE681 - Software Modeling & Analysis, Fall 2015, we are exploring the development of a noSQL database in a series of five projects:
-
Project #1
Develop the concept for a basic noSQL application. We capture the concept with an "Operational Concept Document" (OCD). -
Project #2
Implement most of the concept and perform thorough functional tests. -
Project #3
Develop the concept for a remote noSQL application, based on Project #2, using a message-passing communication service. -
Project #4
Implement the remote noSQL database server and do performance testing. -
Project #5
Create and document a data management service architecture using the ideas developed in the first four projects. This service will provide the communication and state management infrastructure for a large Software Development Collaboration System composed of a federation of cooperating servers and client controllers.
Documenting critical issues helps us think critically about our ideas and planned implementation before committing to code. We may find that biasing our design in one direction or another may support the spinning off of new applications and services from a solid base. We might also find that there are significant impediments on the path we are embarking and force a rethinking of the application and its goals.
Concept -> Uses:
In the projects for this course, we will be concerned with storing very large data sets, accepting data from streams quickly, storing and accessing networks of data, and managing collections of heterogeneous data.
In the final project this Fall we will investigate the feasibility of building a data management service for a large collaboration system. That involves: managing a large repository's data, recording continuous integration and test activities, managing notifications to a large collection of clients, and building and maintaining templates for test configurations, collaboration sessions, work package descriptions, etc.
For the first project, however, uses focus on understanding requirements needed to implement a noSQL database, exploring alternative structures, and demonstrating the implications of our design choices. The users are the developer, Teaching Assistants, and the Instructor. Essentially each student developer is responsible for demonstrating that each of the requirements in the Project 2 statement have been met.
The design impact of this use is that the implementation must carefully demonstrate requirements in a step-by-step fashion. When a requirement asks for the ability to change some aspect of the database state it is the design's responsibility to show the state before, display the nature of the change, and display the database state after the change. This should be done trying to make the display as economical as practical so limiting what an observer must understand to verify the action.
Concept -> Structure:
Perhaps the easiest way to begin creating a structure for an application we're developing is to think about the tasks it must execute. The project statement for Project #2 requires the noSQL prototype to provide the capability to:
- Create items described by metadata and holding an instance of some generic type.
- Create and Manage a Key/Value database with capability to store and delete Key/Value1 pairs.
- Edit Values
- Persist database contents to an XML file2.
- Augment database contents from an XML file with the same format as persisted, above.
- Support a variety of queries, both simple and compound.
- Support demonstration of all functional requirements through a series of discrete tests with display to the console.
Each database Value has structured meta-data and an Instance of the generic type. We will choose to create a C# class to represent Values that might look something like this:
public class Value<Key,Instance>
{
// public methods providing
// access to private data
private string name; // Note: you may choose to capture
private DateTime timeStamp; // these Value states as properties
private string description; // rather than private data items.
private List<Key> children;
private Instance payload;
}
and a C# class representing the database engine:
public class noSQLdb<Key,Value>
{
// public methods providing database API
private Dictionary<Key,Value> // The dictionary should not be a public property.
}
Each task in the list at the top of this section is a candidate to become a package. Some we may decide to merge later. There may also be times to take an existing package and divide into smaller packages. Usually that happens when the original was becoming too complicated to test easily. Finally there may be a very few packages that we didn't have the foresight to define in the concept, but discover a need for during implementation.
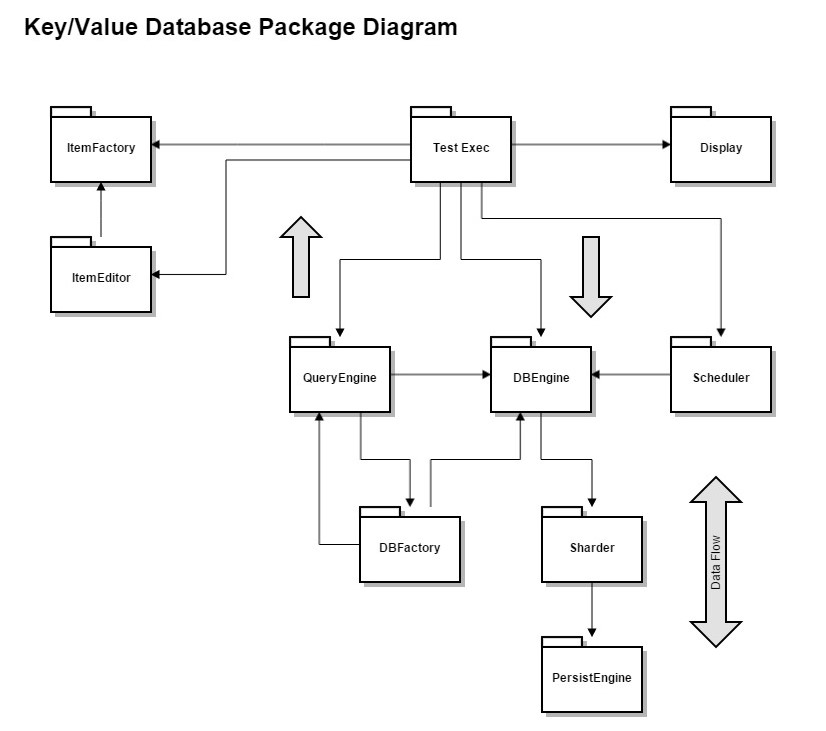
We start with a TestExec package at the top that is responsible for the project's main use - demonstrating that requirements have all been met.
TextExec creates instances of Key/Value pairs using a simple factory that may generate a unique key and construct a Value with supplied parameters.
It uses those pairs to populate its noSQLdb instance through an API provided by the DBEngine package.
The nature of query processing and sharding are the most interesting parts of this project and will be left to students to work out in their individual ways.
The remaining parts are self-explanitory after reading the Project Statement.
When an application is large or becomes complex we often provide a top-level package diagram, like this one, and later provide more package diagrams for individual parts with significant internal structure.
We almost always provide activity diagrams to help OCD readers understand the intent of the concept. The OCD for this project would greatly benefit from activity diagrams for handling queries and for sharding. These are left for students to provide.
Concept -> Critical Issues:
-
Issue: - Demonstrating Requirements
Students only get credit for requirements they clearly demonstrate. No inputs other than a supplied XML file to load the intial database are required3. The only output required is a console display.
Solution:
This requires careful orchestration of a series of tests invoked by the test executive and supported by processing in the Display package.
Impact on Design:
It will be effective to provide a method for each test that announces the Requirement number and displays db state before and after each change. -
Issue: - Designing Queries
Statement and solution(s) are left to the students. -
Issue: - Sharding
Statement and solution(s) are left to the students. - More Issues: - Left to Students.
Later Projects:
After completing Project #2 we work on a concept, in Project #3, and implement, in Project #4 remote access to the noSQL prototype via message-passing communication.
Finally we develop an architecture, in Project #5, for a data management service in a large Software Development Collaboration Environment using the NoSQL model we created in the earlier projects.
You will find that several noSQL databases are required for Project #5 and that the key types and value types will not all be the same. I would expect that sharding strategies may vary from database to database. For that reason, it would be interesting to support pluggable sharding strategies in our noSQL design. You should probably address that as a critical issue in your OCD for Project #14.
Concept Revisited:
All the discussion that follows was added after students turned in their noSQL Operational Concept Documents. This discussion is concerned with things I wanted students to think about without being given too much guidance, but now want to clarify before they begin their designs for the noSQL Database. We will focus on Queries, Sharding, and say a couple of things about the ItemFactory.
Queries:
First, what is a query for this nonSQL database? Let's define that in parts:
- A QueryPredicate is a function that accepts a db key and returns true or false depending upon the processing of the predicate function. For this noSQL db, the processing will look for specific conditions in the element bound to the supplied key, e.g., name, description, time-date stamp, children, or payload.
- A simple query then, consists of applying the QueryPredicate to each of the keys in the database and collecting all of the keys for which the predicate is true.
- A compound query is a chain of queries, each query using the keyset returned by the previous query5.
Suppose that we wrap each query return in an object that holds the resulting keyset and has the same reading interface (keys(), getValue(key, out val)) as the DBEngine but doesn't have any writing methods. We'll call that VirtualDBEngine. Suppose that we define a C# interface, IQueryable, that declares those "reading" methods and have both VirutalDBEngine and DBEngine implement that interface. Then each step of the compound query acts on an IQueryable object which, for the first query in the compound chain acts on a DBEngine instance and on every subsequent query clause acts on a VirtualDBEngine instance.
With that setup we can define the showDB methods to use the IQueryable interface so it can be applied at each step of the query.
DBFactory is the facility that makes a simple query and returns an IQueryable instance6.
QueryEngine is configured with a set of QueryPredicates, uses the first on DBEngine to get an IQueryable with the first keyset, and uses each successive query on the returned IQueryable to refine the keyset returned by the previous simple query.
You can think of the QueryPredicates to be equivalent to stored procedures in a conventional database.
- The C# language has two kinds of types: value types and reference types. Value types reside in static or stack memory, are copyable, and when assigned are unique from the original source. Reference types reside in managed memory and are, in general, not copyable nor assignable. The program's code may copy or assign a reference to an instance on the managed heap, but both target and source of the reference copy or assignment are the same heap-based instance. Our use of the term Value in this blog does not mean a C# value type. It simply means the database data referenced by the key. The kind of it's type may be either a C# value or C# reference type.
- Project #1 encourages students to think about issues like sharding. We do not require students to implement sharding in Project #2 but would be pleased to see and review any sharding processes they may attempt.
- Please do not provide console menues. A GUI could be effective for Project #2 but I would much rather have you spending your time working on the functional requirements.
- This is a test to see if you've read the entire blog carefully before submitting your first project.