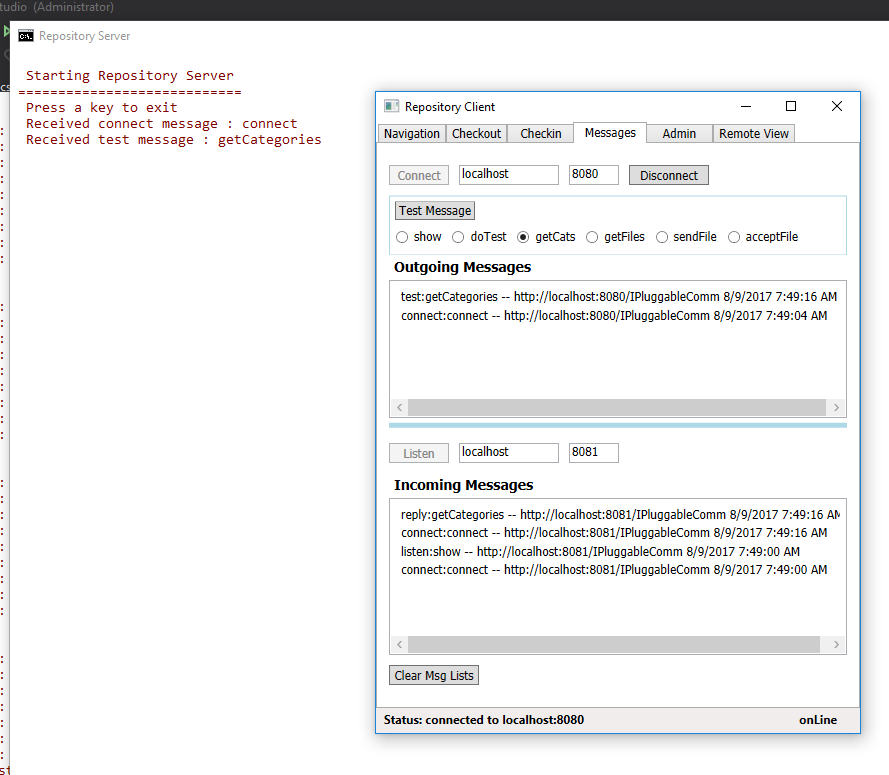
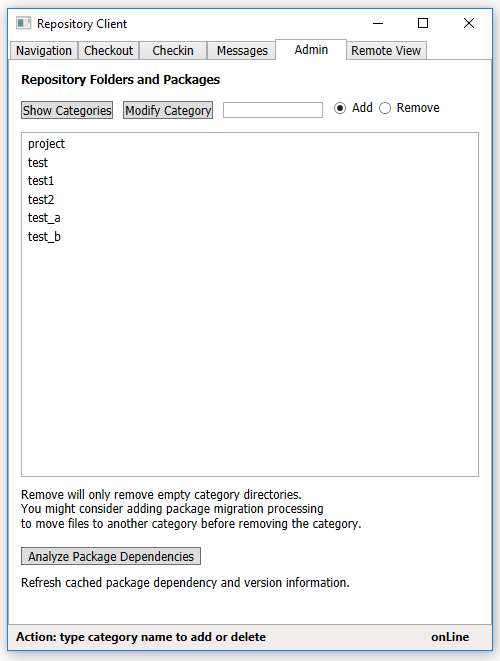
- Categories list
- versioned files and metadata in a category
- source code and metadata for a specified file
Concept:
The Pluggable Repository is composed of an application that loads libraries, at runtime, and provides all of the major functionalities required to manage a code baseline. This structure allows a software engineering organization to customize the repository for its own style of product management. Organizations usually have a process they use for building and managing a baseline which may differ from the way others do that. The Repository has a library for each of its major activities, allowing customization by simply using a different existing library or creating a new library for any of its functions. Another part of the concept is the use of dependency-based storage. That allows a user to extract a package and all the other packages it depends on simply by naming the root package of that dependency subtree. This makes frequent building and testing of parts of the baseline much easier because we extract all of the parts needed for the build with one extraction request, without getting a lot of packages that are not needed.
Repository Storage Structure - Metadata and Files